COSC 3340 – Introduction to Automata and Computing
Solution for Exercise Set 1
(Fall 2003)
Instructor: Dr. Rakesh Verma
TA: Razi A. Syed
|
Problem 1a |
|||||||||||||||||||||||||||||
|
|
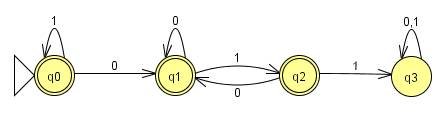
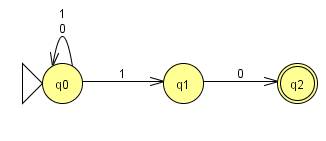
DFA for {w Є {0,1}* | w does not contain the sub
string 011}
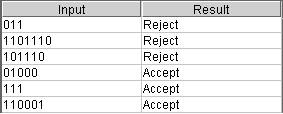
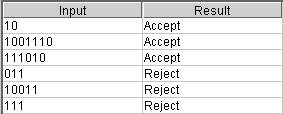
Test Results:
|
||||||||||||||||||||||||||||
|
Problem 1b |
|||||||||||||||||||||||||||||
|
|
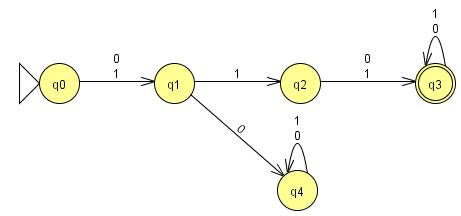
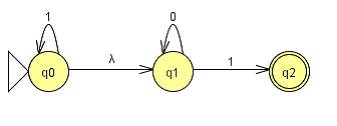
DFA for {w Є {0,1}* | w has length at least three
and its second symbol is 1}
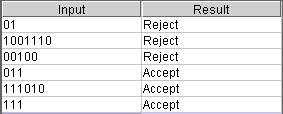
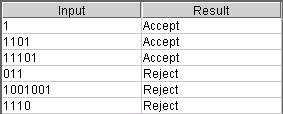
Test Results:
|
||||||||||||||||||||||||||||
|
Problem 2 |
|||||||||||||||||||||||||||||
|
|
S = {a, b, c, d} Binary Relation R = {(a, a), (a, d), (a, b), (b, a),
(b, c)} Reflexive Closure of R: Before we can answer this question, we have to understand
what Reflexive Relation means.
The Reflexive Closure set will be all the elements in R,
including the elements that are required for R to be closed under reflection.
Therefore, the Reflexive Closure set is {(a, a), (b,
b), (c, c), (d, d), (a, d), Symmetric Closure of R: Again, we first need to understand Symmetric Relation.
The Symmetric Closure Set of R is {(a, a), (a, d), (d, a), (a, b), (b, a), (b, c), (c, b)}, as this set is closed under R. Transitive Closure of R:
For our problem, the Transitive Closure of R is {(a,
a), (a, d), (a, b), (b, a), (b, c), (a, c), (b, d),
(b, b)} |
||||||||||||||||||||||||||||
|
Problem 3 |
|||||||||||||||||||||||||||||
|
|
Given: and where |
M1 = (Q1, Σ, δ1,
s1, F1) and M2 = (Q2, Σ, δ2,
s2, F2) M = (Q, Σ, δ, s, F) Q = Q1 x Q2 s = (s1 x s2) δ = ((q1, q2), s) =
(δ1 (q1, s), δ2 (q2, s)) F = F1 x F2 |
|||||||||||||||||||||||||||
|
|
We need to prove: L(M) = L(M1) Ç L(M2) One way to prove the above is by Contradiction. Let us assume that our premise that L(M) is the
intersection of L(M1) and L(M2) is not true, |
||||||||||||||||||||||||||||
|
|
i.e. |
Assume: L(M) ¹ L(M1) Ç L(M2) |
|||||||||||||||||||||||||||
|
|
Based on the above assumption, we can derive two
implications: One is that if w Î L(M1) and w Î L(M2), then it is
implied that w Ï L(M). Second is that if w Î L(M), then it is implied that w Ï L(M1)
and w Ï L(M2). We need to get contradictions for both the implications,
hence our proof will have two steps. Step 1: Show that if w Î L(M1)
and w Î L(M2),
then it is implied that w Î L(M) Let us choose a word “w” such that w Î L(M1)
and w Î L(M2).
Since w is in both languages, and we are assuming that M does not accept such
words, therefore based on our assumption, w Ï L(M). But if w Î L(M1),
then that means that there is a set of transitions δ1*Î δ1
such that |
||||||||||||||||||||||||||||
|
|
|
δ1* (s1, w) = ff Î F1
|
(In other words, there are transitions in δ1
that accepts “w”) |
||||||||||||||||||||||||||
|
|
Similarly, we will have transitions in δ2
that accepts “w”. |
||||||||||||||||||||||||||||
|
|
i.e. |
δ2* (s2, w) = f2 Î F2 |
|
||||||||||||||||||||||||||
|
|
From the way we have defined F, it implies that if a word
ends up in F1 and F2, it has to end up in F also, which
means that the word will be accepted by M. |
||||||||||||||||||||||||||||
|
|
i.e. |
δ* ((s1, s2), w) = f Î F |
|
||||||||||||||||||||||||||
|
|
Therefore, we have shown that if w Î L(M1)
and w Î L(M2),
then it is implied that w Î L(M),
and we have a contradiction to our assumption. Step 2: Show that if w Î L(M),
then it is implied that w Î L(M1) and w Î L(M2) Let us choose a word “w” such that w Î L(M).
Based on our assumption, since w is in L, it will be rejected by both L(M1)
and L(M2), i.e. w Ï L(M1)
and w Ï L(M2). If w Î L(M),
then that means that there is a set of transitions δ*Î δ
such that w will be accepted, and will end in state that belongs to the set
of final states (F) for Q. |
||||||||||||||||||||||||||||
|
|
i.e. |
δ* ((s1, s2), w) = f Î F |
|
||||||||||||||||||||||||||
|
|
Now F is defined as F1 x F2, which
implies that if we have a final state in F, it must also belong to both F1
and F2. i.e. f Î F => f Î F1 and f Î F2. Now if f Î F1, it follows that w Î L(M1).
Similarly, f Î F2
implies that w Î L(M2).
Hence we have shown that if w Î L(M), then it is implied that w Î L(M1)
and w Î L(M2),
and we have a contradiction to our assumption. We have shown that in both implications of our assumption,
we get a contradiction, therefore due to contradiction, our assumption must
also be false. |
||||||||||||||||||||||||||||
|
|
i.e. which
implies that |
L(M) ¹ L(M1)
Ç L(M2)
is not true. L(M) = L(M1) Ç L(M2) |
|||||||||||||||||||||||||||
|
|
Hence we have proved that M generates the language that is
the intersection of language generated by M1 and M2. |
||||||||||||||||||||||||||||
|
Problem 4a |
|||||||||||||||||||||||||||||
|
|
NFA for {w | w ends with 10} with 3 states
Test Results:
|
||||||||||||||||||||||||||||
|
Problem 4b |
|||||||||||||||||||||||||||||
|
|
NFA for the Language 1*0*1 with 3 states
Test Results:
|
||||||||||||||||||||||||||||
|
Problem 4c |
|||||||||||||||||||||||||||||
|
|
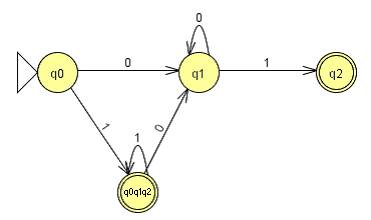
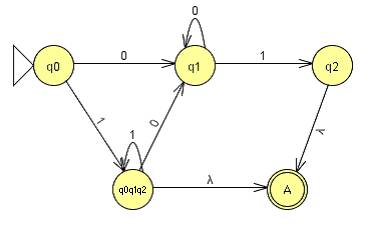
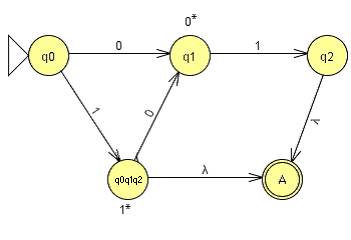
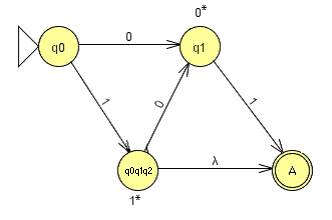
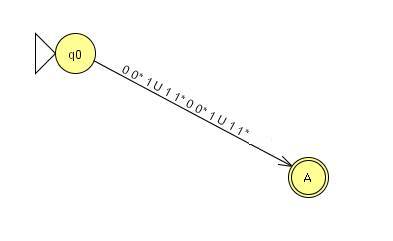
DFA by construction:
Regular Language by Construction: Step 1: Draw out the Automata. Note that we can omit
drawing the NULL state, as it will be eliminated eventually.
Step 2: Add a new and ONLY Final State “A” and make ε
transitions from the final states in to this new final state.
Step 3: Change the loops to “*”.
Step 4: Start removing states one by one, by uniting and
concatenating the string they would create. After removing q2, we get:
After removing q0q1q2, we get:
Finally, after removing q1, we get:
The answer that we come up with is: (0 0* 1) U (1 1* 0 0* 1) U (1 1*), which looks a lot different from the original regular language given in 4b, but if we observe the language generated by this regular language, it is exactly the same. |
||||||||||||||||||||||||||||
|
Problem 5a |
|||||||||||||||||||||||||||||
|
|
Given, L = {bn am | m, n >=
0}, what is Suff(L)? To solve this problem, first we have to understand what
“Suffix” of a string is. Simply, suffix is the end characters of a string.
There could be more than one suffix of a string. For example, let us take a string, “texas”. One suffix of this string could be “s”, or “as”, or “xas”. The complete set of all suffixes for the string “texas”
would be: {“s”, “as”, “xas”, “exas”, “texas”, ε} Note that both the empty string, and the string itself are
considered as suffix of the string. Now let us observe the language L. It can generate any
number of “b”s followed by any number of “a”s, and the empty string is
included in the language. We are required to provide Suff(L), which will be a
language that generates all the suffixes of each string by L. By definition, we already know that Suff(L) will be at
least be equal to, or a superset of L, as Suff(L) generates each word
generated by L. A few of the strings generated by L are ε, “a”, “ba”,
“bba”, “bbba”, and so on. If you notice, each string in the list is a suffix for the
string ahead of it. There are many different possibilities of such lists, and
L will accept each one of them. We can also take a few more examples, like
“bbbbbaaaaa”, “aaaaa”, or “bbbbb”. L will accept all suffixes of each of
these words. If we notice carefully, we can conclude that the language
L itself is capable of generating all the suffixes of any word it can
generate. In fact, L can generate ANY sub string of any word it can generate.
Therefore, one easy solution to our problem is: Suff(L) = L. |
||||||||||||||||||||||||||||
|
Problem 5b |
|||||||||||||||||||||||||||||
|
|
Given that L is regular, prove or disprove that Suff(L) is regular. One approach to solving this problem could be as follows: Since we know that L is regular, we can design a DFA, M,
which can accept all words in L. Now if we want our DFA, M, to accept any
suffix of any string in L, only a small change to the DFA M will do that.
What we need to do is introduce a new starting state, and make ε
transitions from this starting state to each state already existing in the
DFA M. After this change, the new NFA will accept all suffixes of the strings
accepted by the language L. Let us understand how this works with an example. Let us
say that “texas” was accepted by L, and therefore we had transitions in the
DFA, M, to accept “texas”. Now after introducing the new initial state with
ε transitions to each state, lets say we wanted to accept “xas”. We can
follow the ε transition to state where “x” initiated, and then follow
the transitions to generate “a” and “s”, and accept the word. After the change, we will have a new NFA M’, but the
machine can still be converted to a DFA, and therefore the language it
accepts is Regular. Since the language that M’ accepts is Suff(L), therefore
Suff(L) is regular. Formally, Define DFA, M = (Q, Σ, δ, q0, F) such
that L (M) =
L Define NFA, M’ = (Q’, Σ, δ’, qs, F)
as follows |
||||||||||||||||||||||||||||
|
|
and |
Q’ = Q U { qs } and δ’ : δ U ({qs} x {ε} x Q) L(M’) = suff(L) |
|||||||||||||||||||||||||||
|
|
|
||||||||||||||||||||||||||||