Human Motion and Behavior Analysis
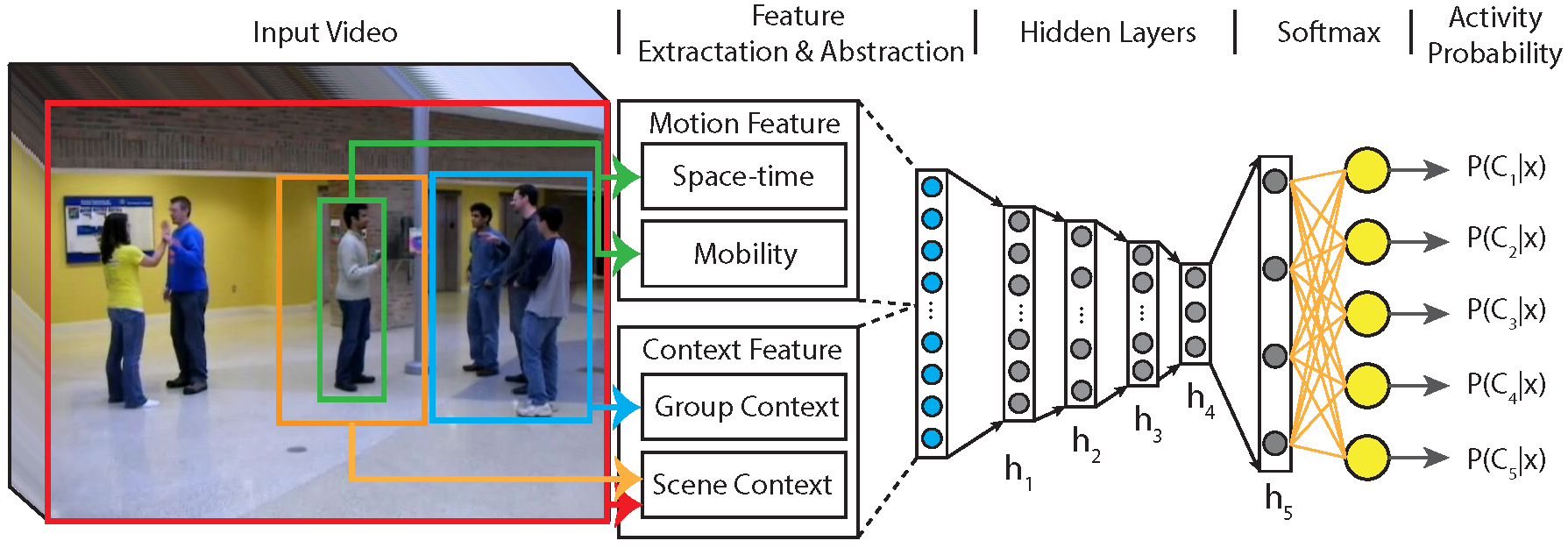
Human behavior has been extensively studied by sociologists to understand social interactions and crowd dynamics. It has been argued that characteristics that dictate human motion constitute a complex interplay between human physical, environmental, and psychosocial characteristics. It is a common observation that people, whenever free to move about in an environment, tend to respect certain patterns of movement. More often, these patterns of movement are dominated by social mechanisms. While much of computer vision has focused on studies that try to model the physical and environmental characteristics, psychosocial influences have largely been overlooked. Broadly speaking, human motion attributed to psychological and sociological characteristics may be evaluated at three distinct levels; individual, interaction among individuals, and group dynamics. Studies of collective locomotion have shown that social interactions play an important role in structuring human behavior, which in turn influences local human motion. Humans when together in large gatherings orient their actions to each other and move in concert with each other. In contrast, individuality of a human and the notion of accounting for independent decision making ability leads to possibilities of emergent behaviors. Human movements are generally driven by purpose, making decisions locally based on the extent of information available and the cognitive capacity for calculation, prediction, and action. Each of these distinct observations have led to formalisms that either try to model human motion dynamics as a flow with fluid-like properties or consider human motion to be individualistic with local interactions leading to complex dynamics. The prior formalism assumes the motion of individuals to follow the overall dynamics in an environment to maintain continuum while the latter focuses on self-organizing effects. In either case, our ability to increase our understanding of human motion and activity can be extended through the development of models and algorithms that integrate social cues that codify human behavior. Our interests and research efforts in this area have led to contributions of algorithms that propose models to code human-human and human-environment interactions through fundamentals of proxemics. These have been successfully applied to problems in human tracking, detection of groups of people, human group activity recognition, and leveraging of group structures for re-identification of humans across distributed camera networks. This research has been and continues to be supported in part by the National Institute of Standards and Technology, US Army Research Labs and the Department of Justice.
Wide-Area Surveillance

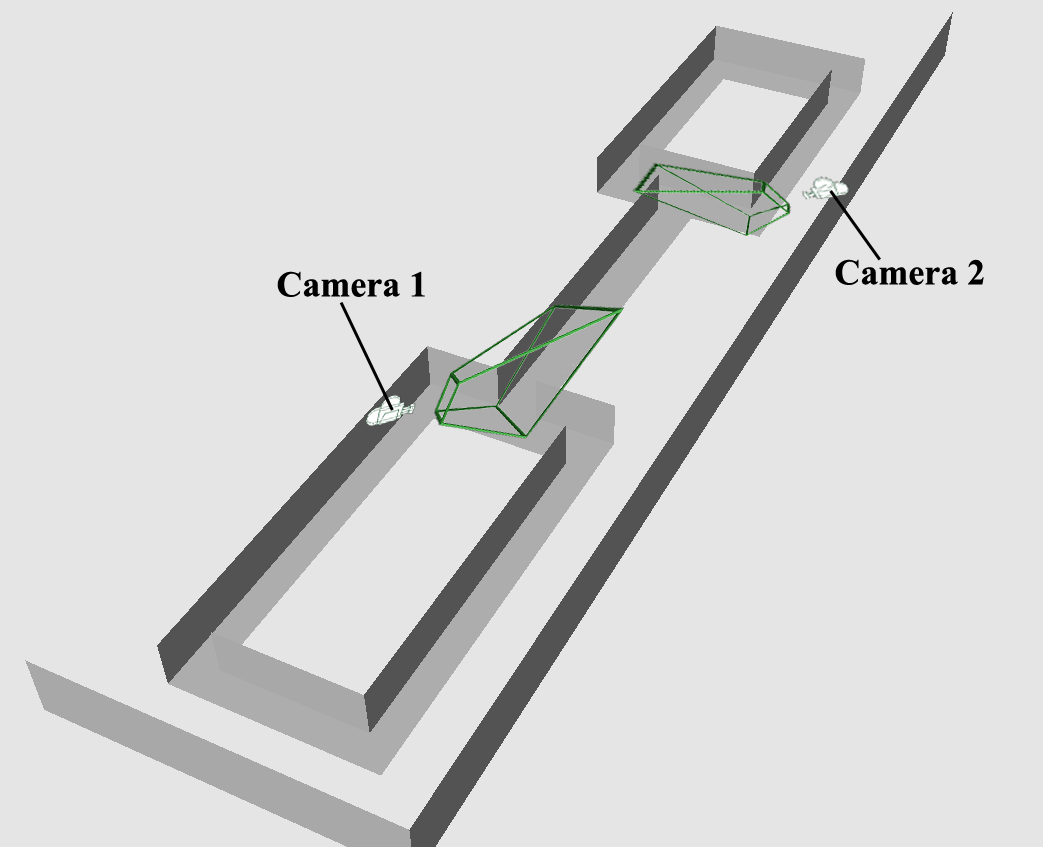
This effort is related to the problem of target acquisition, tracking, and recognition in a sparse sensor network. While multiple cameras with overlapping field of view can enhance the capability and performance of video surveillance applications, providing fault-tolerance and robustness for issues such as object occlusion by achieving overlapping field of views across a large multi-camera network is not always feasible. This requires coordination and synchronization of cameras within the network, which is not dependent on the target object. In addressing these challenges, our research goals have been to develop an intelligent, non-obtrusive, real-time, continuous monitoring system for assessing activity and predicting emergent suspicious and criminal behavior across a network of distributed cameras. The envisioned system consists of two main modules, namely: 1) A non-obtrusive tracking system that can continuously: i) track all objects across a network of distributed cameras, ii) analyze the spatio-temporal movement pattern of each object, and iii) detect and measure descriptive information continuously of each tracked object. 2) A decision system that can: i) correlate each object’s spatio-temporal patterns with others and generate models of suspicious/criminal activity, and ii) generate activity alerts for security personnel who monitor and make critical decisions. To that extent, over the past 5 years, we have successfully functionalized a state-of-the-art distributed surveillance camera network with over 25 cameras (indoors and outdoors) for data collection and validation studies; developed multi-human tracking algorithms capable of robust object label management and trajectory generation, developed algorithms for human reacquisition (re-identification) across non-overlapping cameras; and developed models and algorithms for activity analysis. In addition, more recently, we have also developed algorithms for recovering (predicting) motion trajectories of tracked objects across non-overlapping cameras. This research has been and continues to be supported in part by the US Army Research Labs, The Texas Advanced Research Program, National Science Foundation, and the Department of Justice.
Facial Analysis

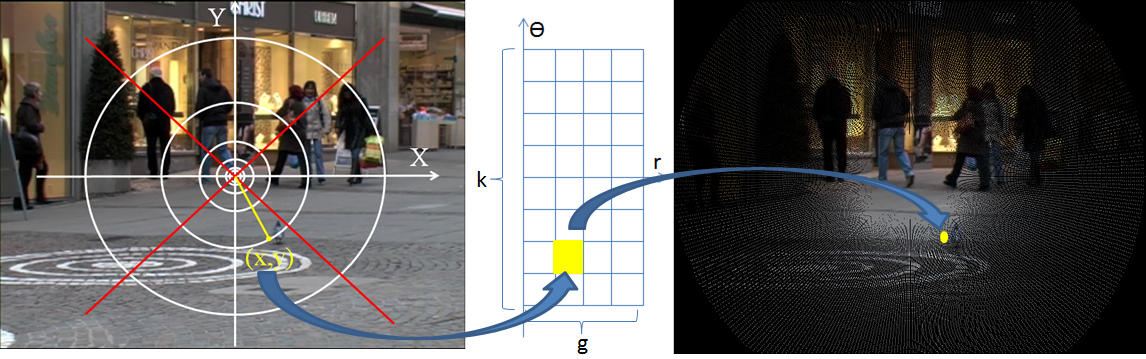
Face recognition is one of the most attractive biometric since it can be done passively and unobtrusively at a comfortable distance. In addressing the challenges across the multitude of applications, many face recognition systems have been developed over the past few years. Most facial matching systems rely on two-dimensional (2D) facial images and their performance is broadly affected by varying illumination conditions, change in pose, and poor image quality (e.g., blurry images, low resolution). Systems leveraging strictly 2D facial image analysis have high false accept/reject rates, suboptimal response time scaling with database size, and strict pose/illumination acquisition requirements. On the other hand, three-dimensional (3D) face recognition does not suffer from inherent problems of pose and illumination variations. Nonetheless, it is not feasible to limit such systems to only 3D data. Thus, there is a technology gap between these two types of systems (2D vs. 3D). Our research interests and goals have been to bridge this gap by specifically addressing facial matching under availability of 2D images. The driving hypothesis has been that through the use of 3D model of the face and by addressing variations related to pose, illumination, and resolution, it is possible to improve face matching and in general facial analysis. To that extent, much of our research contributions have been related to developing methods and systems for face recognition, facial image super-resolution, illumination modeling and correction, facial landmark detection, and robust facial signature extraction. This research has been and continues to be supported in part by the US Army Research Labs, and the Intelligence Advanced Research Projects Activity.