|
Scalable Data Summarization to Compute Machine Learning Models |
|
Sikder Tahsin Al-Amin
|
|
We generalize a data summarization matrix to produce one or multiple summaries, which benefits a broader class of models.
Our solution works well in popular languages, like R and Python, on a single machine, and shared-nothing architecture in parallel.
A key innovation is evaluating a demanding vector-vector multiplication in C++ code, in a simple function call from a high-level programming language.
Our method in the R language is faster and simpler than competing big data analytic systems computing the same models, including Spark
(using MLlib, calling Scala functions) and a parallel DBMS (computing data summaries with SQL queries calling UDFs)
|
 |
|
Graph Analysis |
|
Xiantian Zhou
|
|
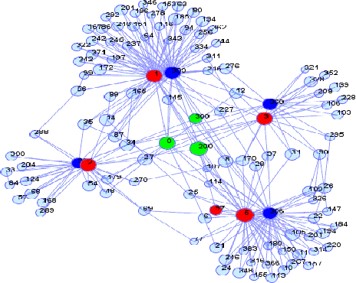
Graph analytics remains one of the most computationally intensive tasks in bigdata analytics, mainly due to large graph sizes,
the structure of the graphs, andpatterns presented in the graphs.
We design and optimize graph analysis algorithms on distributed database systems, specifically,
analyzing graph metrics and graph properties such as betweenness centrality, transitive closure, triangle counting,
etc. We also design and build scalable graph analysis algorithms from scratch on distributed systems using the C++ language.
|
 |
|
Continuous Networks Monitoring |
|
Quangtri Thai
|
|
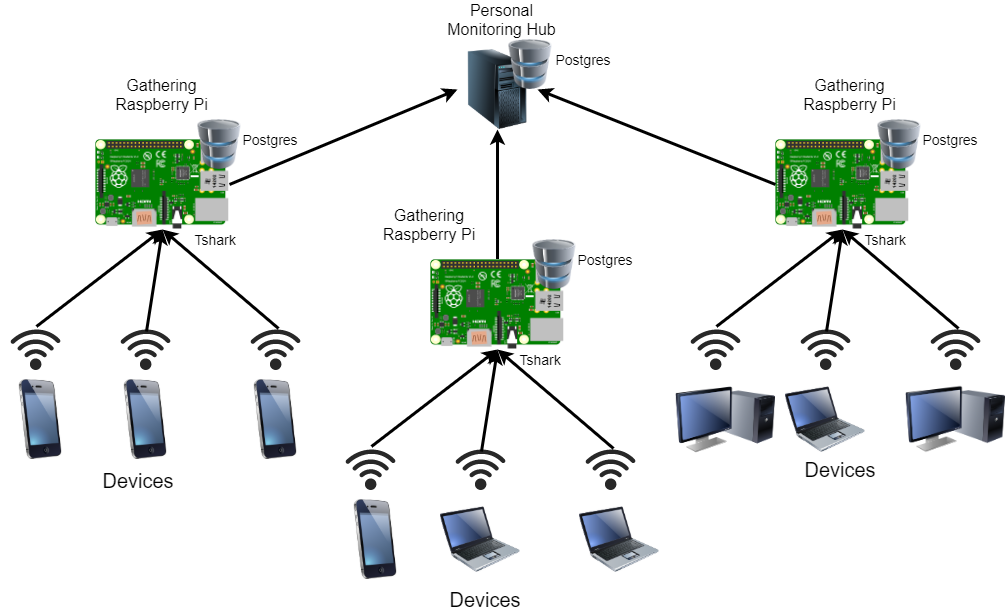
The rise of platforms such as the Raspberry Pis has allowed testbeds to be built at larger scales and in many places around the world. While these testbeds have made much progress, we observe a general lack of standard and flexible data analysis capability to fully take advantage of the resource provided by these testbeds. As such, we leverage the common model used by these testbeds and leverage existing technologies effective in other domains. We model the network instumentation as streaming data processing; formulate different streaming data processing using SQL; and implement and evaluate a light-weight DB and SQL-based network instrumentation system on an edge device in a distributed architecture.
|
 |
|
Interactive Compiling of C/C++ in Python |
|
Quangtri Thai
|
|
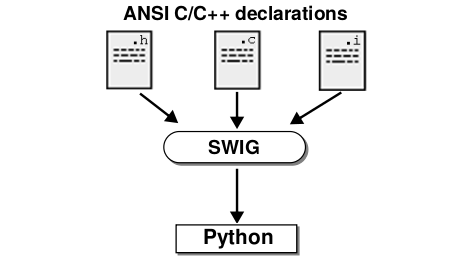
Given Python's simplicity and popularity in data analysis, it becomes more enticing to use Python. The downside, however, comes from the fact that Python is not as efficient as languages such as C/C++. As such, we look to combine both Python and C/C++ by wrapping more intensive code in C/C++ using Swig to use in Python. We look to take advantage of the many tools provided by Swig to create a seamless integration between C/C++ and Python, detailing an easy way to maintain the wrapped code and employing the C/C++ code using Python's intuitive syntax.
|
 |
|
OLAP Statistical Test |
|
Zhibo Chen
|
|
Finding an efficient and error-proof
method for isolating factors that
significantly cause a measured value
to change is an ongoing problem
faced by statisticians. Therefore,
we are creating a tool that utilizes
the exploratory power of OLAP cubes
along with statistical tests to
create a procedure that produces
statistically sound results. The
easy-to-use interface allows users
to discover significant metric
differences between highly similar
populations without need for
educated guesses. A GUI is
implemented to create a
user-friendly environment that
allows for easy input, visualization
of progress, partial result viewing,
and pause functionality.
|
 |
|
Bayesian Classifier in SQL |
|
Sasi Kumar Pitchaimalai
|
|
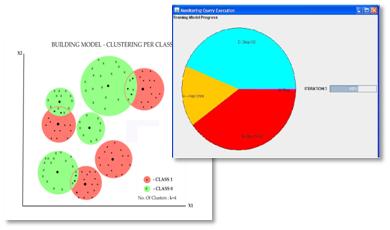
We present a data mining tool, which
implements a Bayesian Classifier in
SQL, based on class decomposition
with the K-means clustering
algorithm. The equations required by
the Bayesian Classifier are
transformed to portable SQL queries.
Several query optimizations are
introduced which make the classifier
more scalable and robust. Since the
classifier is based on clustering
which takes several iterations to
converge, a GUI is used to pause and
resume the iterations while building
the model. The picture on the right
shows the percentage of time
allocated for each step for a single
iteration.
|
 |
|
Information Retrieval in SQL
and Top-K Queries |
|
Carlos Garcia-Alvarado |
|
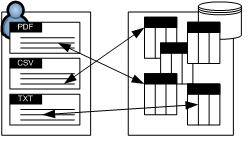
Customarily hard drives have been
used to store documents. However as
the speed of networks and the need
for secure centralized repositories
of information continues to grow, so
does the amount of text data that is
stored in relational databases, and
the need for tools that can process
the data inside the database. The
main difference between this
application and previous research is
the hypothesis that the DBMS can be
exploited to effectively process
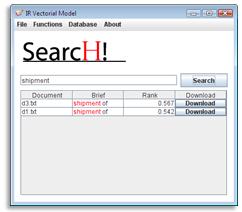
documents. . The objective of the
application is to implement an
information retrieval engine in a
DBMS, allowing fast document storage
and retrieval with DBMS.
|
 |
|
Constrained Associations
Rules |
|
Kai Zhao |
|
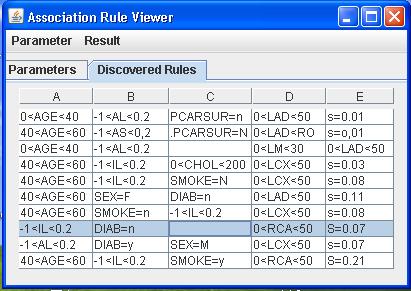
Association rules are a data mining
technique used to discover frequent
patterns in a data set. Real world
application of this technique is
very broad and can include fields
such as medical and commerce. We can
automatically generate the SQL for
creating association rules within a
relational DBMS. We are focusing on
developing several optimizations
that will significantly increase the
efficiency of item set and rule
generation.
|
 |
|
Microarray Data |
|
Mario Navas |
|
We present a system that can analyze
high-dimensional data sets stored in
a DBMS. Such data sets are
challenging to analyze given their
very high dimensionality. We focus
on
computing descriptive
statistics, the correlation matrix
and statistical models derived from
it. Computations are based on
automatically generated SQL queries
and User-Defined Functions. Our
proposal enables fast statistical
analysis
inside the DBMS, avoiding the
need to export data sets.
|
 |
|
Metadata Management and
Document Exploration |
|
Carlos Garcia-Alvarado, Zhibo Chen, Javier
Garcia-Garcia |
|
A federated database consists of
several loosely integrated
databases, where each database may
contain hundreds of tables and
thousands of columns, interrelated
by complex foreign key
relationships. In general, there
exists a lots of semi-structured
data elements outside the database
represented by documents and files.
Our research involves building a
system that creates metadata models
for a federated database using a
relational database as a central
object type and repository. Our goal
is to allow quick and easy querying
that deals with the relationship
between users/files and data within
databases
|
 |